阅读笔记
题目:SSD: Single Shot MultiBox Detector
SSD特点:
- 使用单一深度神经网络
- 网络提取了不同尺度的特征图,自然的处理各种尺度的物体
Model:
标准的卷积神经网络结构用于整个网络的骨架部分,然后添加一些辅助结构进行目标检测。
-
采用多尺度特征图用于检测
-
采用卷积进行检测
对于形状为$m \times n \times p$的特征图,采用一个$3 \times 3 \times p$小卷积核产生每一个分类的得分,或相对于先验框(default box)坐标的形状偏移
-
设置先验框
先验框以卷积的形式平铺在特征图上,在一个给定的位置上输出k个box,对每一个box计算x个scores(对应x类,这x类中包括背景),以及相对于先验框坐标的4个偏差值。因此在$m \times n$的特征图上产生$(c+4)kmn$的输出。
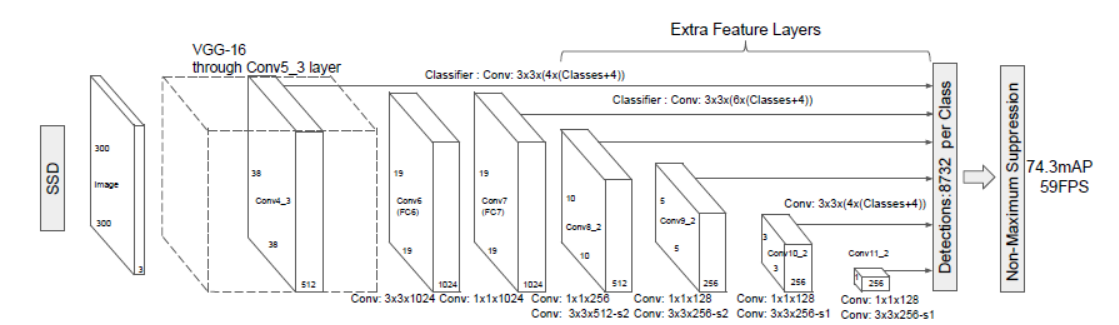
文章采用的模型中首先采用VGG16作为基础模型,具体如上图所示,同时在特定的卷积层采用空洞卷积,以达到不增加参数与模型复杂度的条件下指数级的扩大卷积的视野。
然后从整个卷积网络中提取6个特征图,分别由Conv_4_3 ($38 \times 38$),Conv_7 ($19 \times 19$),Conv_8_2 ($10 \times 10$),Conv_9_2 ($5 \times 5$),Conv_10_2 ($3 \times 3$),Conv_11_2 ($1 \times 1$)输出,用于目标的位置预测和类别的判断。
文中给出的网络,Conv_4_3、Conv_10_2、Conv_11_2 输出的特征图中的每一个像素点预测4个先验框,Conv_7 、Conv_8_2 、Conv_9_2 输出的特征图中的每一个像素点预测6个先验框,因此最终的输出为:
- cls:(#batchsize,8732,:)
- det:(#batchsize,8732,4)
Training:
-
匹配策略(先验框的匹配)
在训练过程中,首先要确定训练图片中的真实目标(GT)与哪个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。本文中对于图片中每个GT,找到与其IOU最大的先验框,该先验框与其匹配,这样,可以保证每个GT一定与某个先验框匹配。通常称与GT匹配的先验框为正样本,反之,若一个先验框没有与任何ground truth进行匹配,那么该先验框只能与背景匹配,就是负样本。对于剩余的未匹配先验框,若与某个GT的IOU大于某个阈值(一般是0.5),那么该先验框也与这个GT匹配。
-
Hard negative mining
尽管一个GT可以与多个先验框匹配,但是GT相对先验框还是太少了,所以负样本相对正样本会很多。为了保证正负样本尽量平衡,于是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
-
训练目标
损失函数: $L_{conf} \ $ 置信损失函数,$L_{loc} \ $ 位置损失函数,$N \ $ 匹配的先验框数,如果为0,设置损失至0,位置损失函数如下 $x_{ij}^p \in {1,0}$为一个指示参数,当$x_{ij}^p=1$时表示第$i$个先验框与第$j$个GT匹配,并且GT的类别为$p$。$l$ 为先验框的所对应边界框的位置预测值,而 $g$ 是GT的位置参数,$d$为先验框的参数,$(cx,cy)$为中心点坐标,$w,h$为长度宽度。 置信损失函数如下: $c$为类别的置信度。
-
选择先验框的尺寸和长宽比
本文中同时采用低层次和高层次特征图用于检测,但是不同特征图设置的先验框数目不同,先验框的设置,包括尺度(或者说大小)和长宽比两个方面。
先验框的尺度,遵守一个线性递增的规则,即随着特征图的大小降低,先验框的尺度线性增加,具体计算公式如下: $m$为特征图数量,$s_{\min}$最小的先验框尺寸,$s_\max$最大的先验框尺寸,$s_k$第$k$个特征图的先验框尺寸。
对于每个先验框的长宽值用以下公式计算: 其中$a_r$为先验框的长宽比。对于长宽比为1,额外设置了一个尺度为$s_k’=\sqrt{s_ks_{k+1}}$的先验框。
先验框的中心点设置为$(\cfrac{i+0.5}{\vert f_k\vert}, \cfrac{j+0.5}{\vert f_k \vert})$,其中$\vert f_k \vert$为第$k$个特征图的尺寸,$i,j \in [0,\vert f_k \vert)$
Conclusion:
多尺度特征图,利用卷积进行检测,设置先验框,对于小目标检测效果也相对好一点。